The use of hydrologic models such as RORB, for regional and urban flood modelling, greatly increases required model complexity beyond that envisioned when these models were developed. This post outlines the key differences between traditional hydrologic modelling and the complex problems that these models are now being used to address.
Traditional RORB modelling
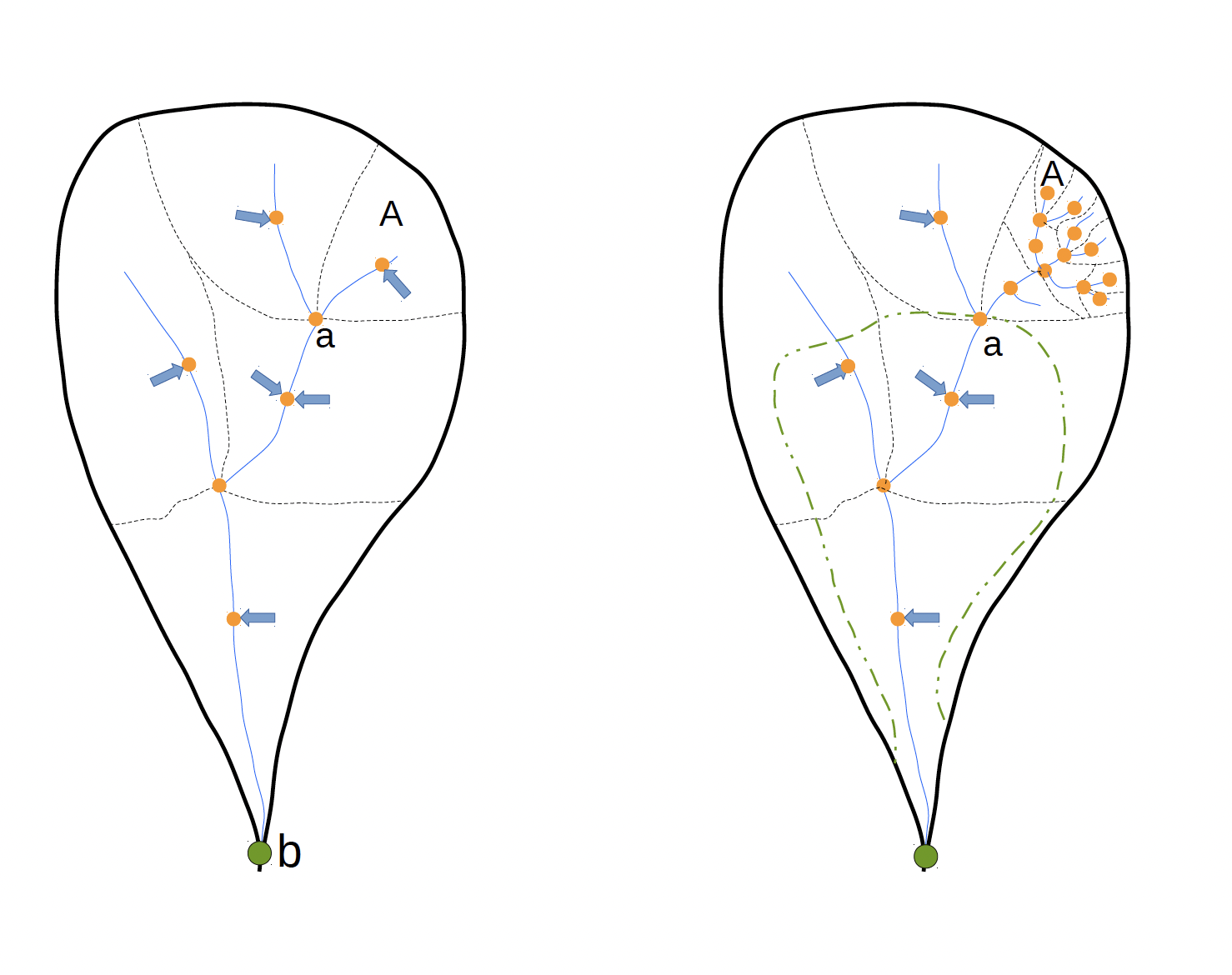
RORB dates from the 1970s and was developed to provide design flood hydrographs usually at a single location at the lower end of a catchment. An example of catchment delineation for a RORB model is show in Figure 1 (left), where a small number of sub-catchments define the set up that can be used to generate a flood hydrograph at node ‘b’. The RORB manual states that between 5 and 20 sub-catchments are sufficient to allow for areal variation of rainfall, losses and the effects of varying flow distance to the catchment outlet. The estimation of RORB parameters for this type of model is reasonably straightforward and is based on the catchment area contributing to ‘b’.
- The design rainfall can be determined by averaging IFD values from the grid of points that covers the catchment.
- Regional relationships can be used to estimate the routing parameter kc as a function of the catchment area or the dav of the model to ‘b’.
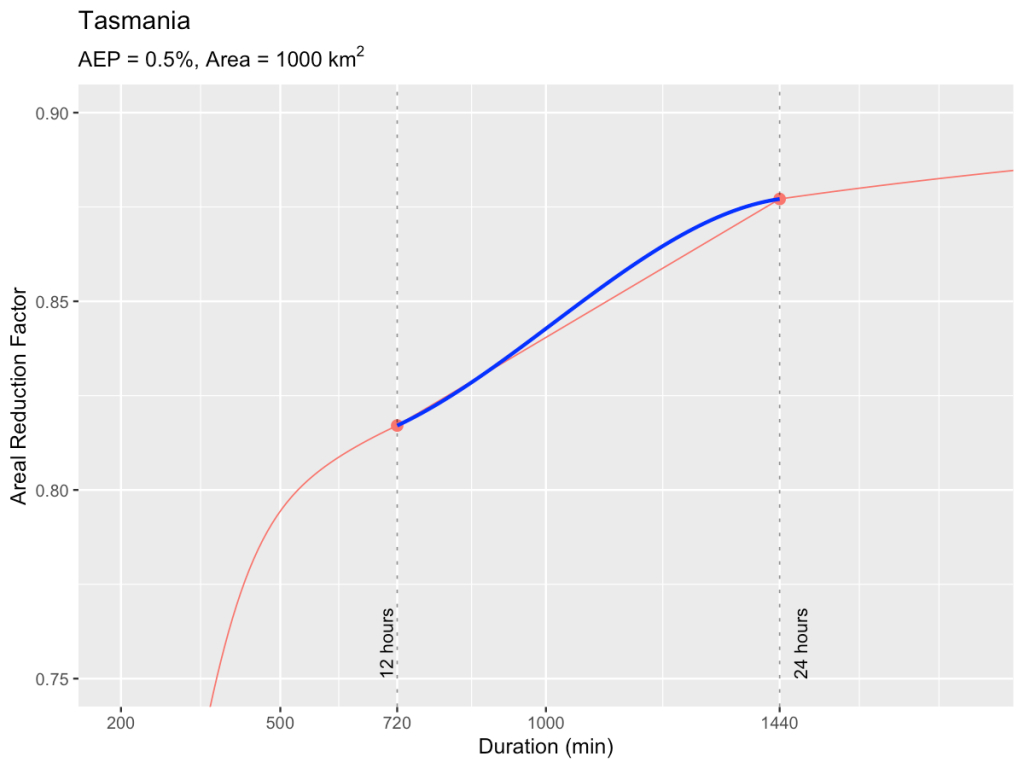
- Areal Reduction Factors (ARFs) are based on catchment area upstream of ‘b’ for a range of durations
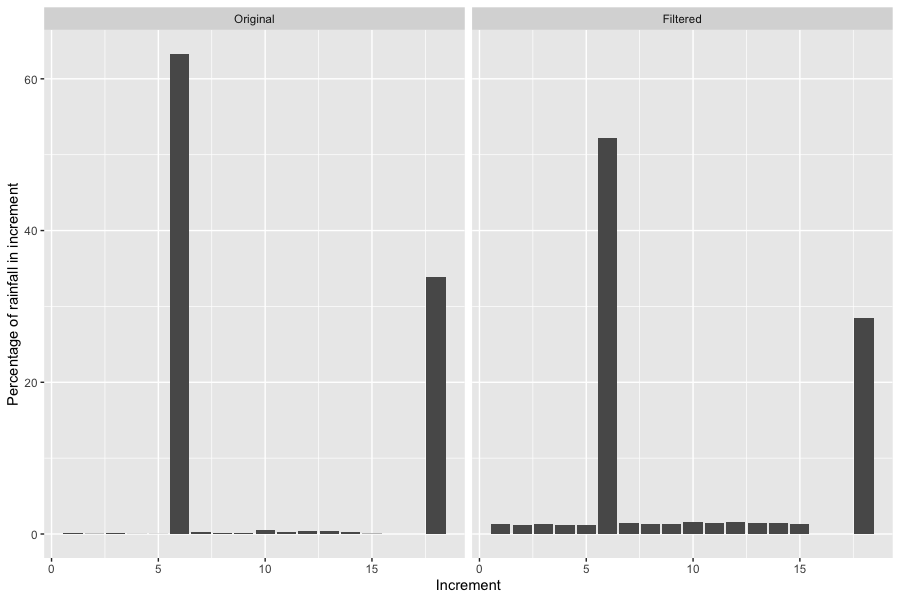
- A spatial rainfall pattern can be derived for the catchment based on the grid of IFD values, for AEPs of interest and the corresponding critical durations.
Use of RORB for regional studies
Applying RORB for regional modelling creates several challenges.
More sub-catchments are required
Shifting to a regional focus increases the number of sub-catchments to be modelled. As shown in Figure 1 (right), a RORB model may be required to generate an inflow hydrograph at ‘a’ for a hydraulic model of a flood prone area (inside the green dashed line). The requirement for a minimum of 5 sub-catchments upstream of ‘a’ means that many small sub-catchments must be defined.
Instead of 5 to 20 sub-catchments being required for the whole model, we need at least 5 sub-catchments for every location where a realistic hydrograph is required. The requirement that sub-catchments must be approximately the same size and shape also contributes to the increase in their number.
This means that the total number of sub-catchments in a regional model can become very large. A key issue is that there is interaction between the number of sub-catchments, RORB parameters (such as kc and losses) and model outputs. I discussed this in an earlier post.
Routing parameters may vary throughout the model
The catchment area of ‘a’ is small so the appropriate kc value will be smaller than for downstream points such as ‘b’. If model outputs at both ‘a’ and ‘b’, or any other location are required, then different kc values will be necessary for each location. This can be achieved in RORB by using interstation areas, or by developing separate models for these locations.
A range of Areal Reduction Factors must be considered
There is a similar issue with Areal Reduction Factors. If hydrographs are required at a number of different locations, then the ARFs will depend on the local catchment area of each of these locations. It is not appropriate to choose a single ARF for the whole model.
The specification of design storms will need to vary throughout the model
The storm that leads to a design flood (e.g. the 1% AEP flood) will depend on catchment size. Flood runoff from larger catchments is likely to be driven by longer duration, higher volume storms compared to floods from smaller catchments. Therefore, different design storms must be used for different locations.
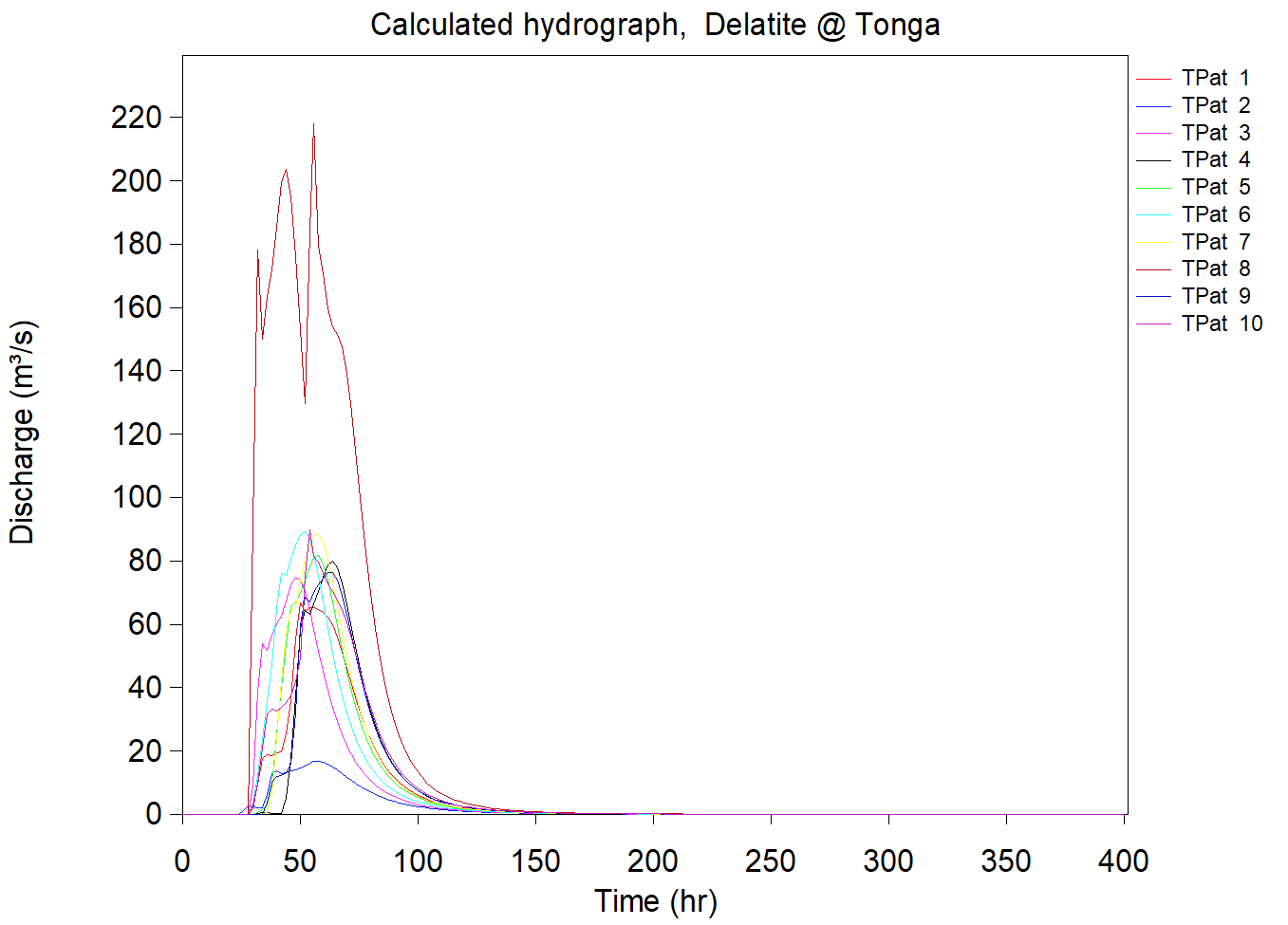
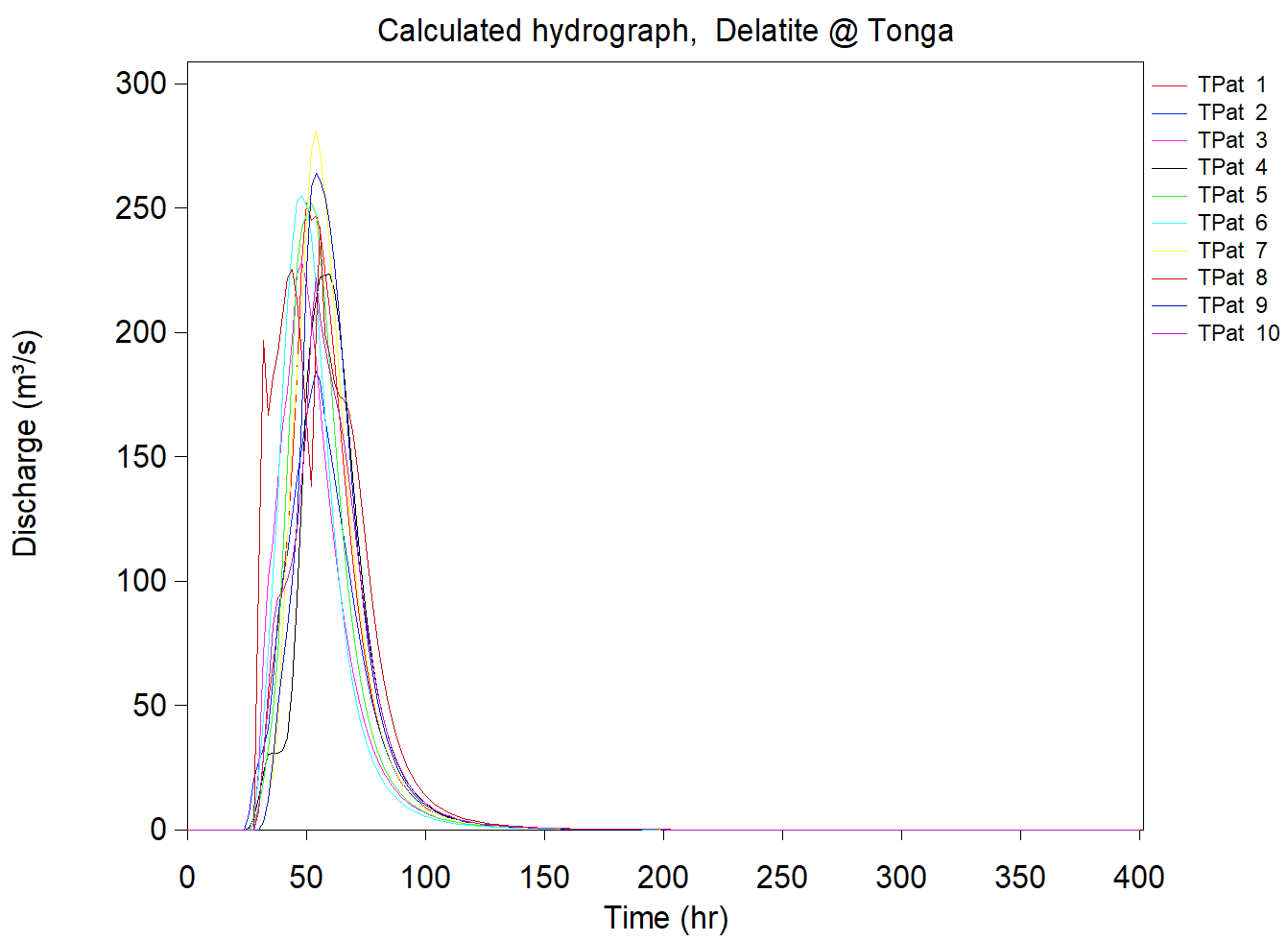
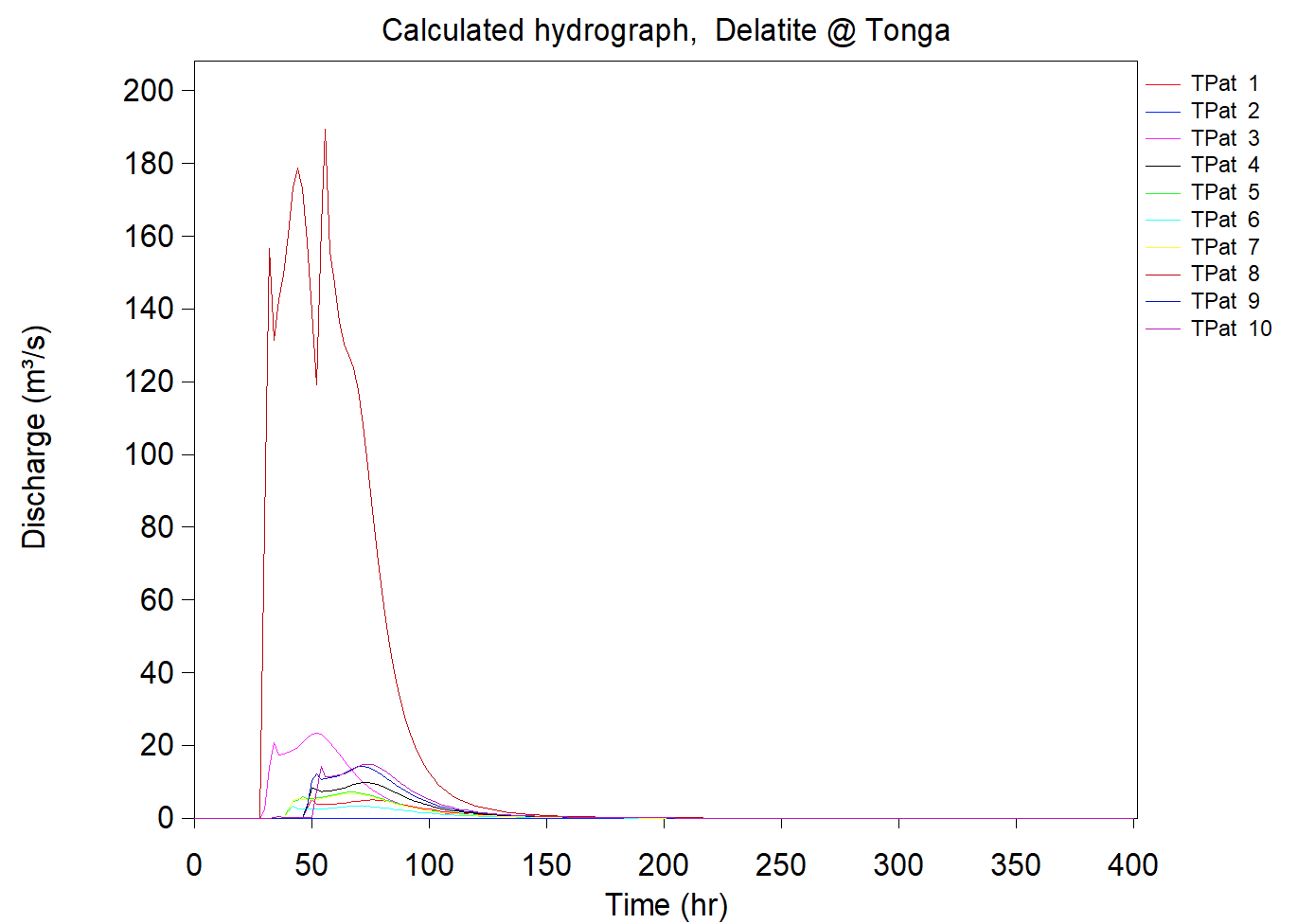
To emphasise the issue, consider points ‘a’ and ‘b’ in Figure 1 (right). If they are a long way apart and with substantially different catchment areas, it is highly unlikely that a single design storm could define the 1% AEP flood at each location. Conversely, if ‘a’ and ‘b’ are close together and with similar catchment areas then the assumption that a single design storm could be used to characterise a 1% AEP flood at each location is reasonable.
A related issue is defining floods for locations with multiple tributaries. The occurrence of 1% floods in each of the tributary catchment simultaneously is likely to be much rarer than a 1% AEP event. Therefore is not appropriate to model 1% AEP floods in several tributaries and assume that this represents the 1% flood at the location where these tributaries combine.
These issues suggest that one approach to the challenge of modelling appropriate design flood hydrographs would be to divide the area of interest into smaller regions and develop hydrographs for each region based on appropriate design rainfalls depths, ARFs, spatial and temporal rainfall patterns, and routing parameters. These hydrographs would be used as inputs to a hydraulic model of the smaller region. The results from all the regions would need to be stitched together to define flood conditions over the whole area.
In summary, the key messages are:
- Modelling a design flood hydrograph for a particular location requires appropriate model setup and routing parameters for that location.
- Similarly, a design storm appropriate for a location must be based on the rainfall depth, spatial pattern, areal reduction factor and losses for the catchment that drains to that location.
- Quantification of flood risk over a large area is likely to require specific model runs for locations within that area and then the stitching together of the results from these model runs to provide the overall results.







![\mathrm{ARF}= \min[1,1-0.287(A^{0.265}-0.439\log_{10}D)D^{-0.36} \\ +0.00226A^{0.226}D^{0.125}(0.3+\log_{10}P) \\ +0.0141A^{0.213}10^{-0.021\frac{(D-180)^2}{1440}}(0.3+\log_{10}P)]](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BARF%7D%3D+%5Cmin%5B1%2C1-0.287%28A%5E%7B0.265%7D-0.439%5Clog_%7B10%7DD%29D%5E%7B-0.36%7D+%5C%5C++%2B0.00226A%5E%7B0.226%7DD%5E%7B0.125%7D%280.3%2B%5Clog_%7B10%7DP%29+%5C%5C++%2B0.0141A%5E%7B0.213%7D10%5E%7B-0.021%5Cfrac%7B%28D-180%29%5E2%7D%7B1440%7D%7D%280.3%2B%5Clog_%7B10%7DP%29%5D+&bg=ffffff&fg=444444&s=0&c=20201002)

![\mathrm{ARF}= \min[1,1-a(A^b-c\log_{10}D)D^{-d}\\ +eA^fD^g(0.3+\log_{10}P) \\ +h10^{\frac{iAD}{1440}}(0.3+\log_{10}P)]](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BARF%7D%3D+%5Cmin%5B1%2C1-a%28A%5Eb-c%5Clog_%7B10%7DD%29D%5E%7B-d%7D%5C%5C++%2BeA%5EfD%5Eg%280.3%2B%5Clog_%7B10%7DP%29+%5C%5C++%2Bh10%5E%7B%5Cfrac%7BiAD%7D%7B1440%7D%7D%280.3%2B%5Clog_%7B10%7DP%29%5D+&bg=ffffff&fg=444444&s=0&c=20201002)